How to Develop a RAG-Powered App: The Ultimate 2025 Guide for CTOs and Product Managers

Meta Description: A comprehensive 2500-word guide on RAG app development. Learn the step-by-step process, tech stack, detailed cost breakdown, and ROI analysis to build a smarter, more accurate AI-powered app for your business in 2025. This guide also covers how a mobile application development company can leverage RAG for groundbreaking Android app development and Flutter app development.
1. The Core Concept of RAG: A Game-Changing Paradigm for AI
The world of generative AI has witnessed a rapid evolution, moving beyond the initial hype of general-purpose chatbots. While Large Language Models (LLMs) like GPT-4 and Gemini are incredibly powerful, their inherent limitation is their fixed knowledge base. They can’t access new, real-time, or proprietary information, which leads to a phenomenon known as "hallucination"—when the model fabricates facts or confidently provides incorrect information. For enterprises, where accuracy and trust are non-negotiable, this is a critical flaw.
This is precisely the problem that Retrieval-Augmented Generation (RAG) solves. RAG is a sophisticated AI framework that augments an LLM's capabilities by providing it with access to a dynamic, external knowledge base. It’s like giving an incredibly smart person a personal, real-time research assistant who can search a vast library of documents and present the most relevant information before they formulate a response.
The RAG process can be broken down into three distinct, yet interconnected, stages:
- Retrieval: When a user submits a query, the system first acts as a smart search engine. It uses an embedding model to convert the query into a numerical vector. This vector is then used to perform a similarity search within a specialized vector database that contains vectorized representations of your entire knowledge base. The system retrieves the most relevant document chunks based on semantic similarity, not just keyword matching.
- Augmentation: The magic of RAG happens here. The retrieved text chunks are then combined with the user's original query to create a new, enriched prompt. This new prompt provides the LLM with the specific, relevant context it needs to generate a grounded and accurate answer.
- Generation: Finally, the augmented prompt is sent to the LLM. The model now has all the necessary information to synthesize a final, factually correct, and context-aware response, which it then delivers to the user.
This approach is a strategic alternative to fine-tuning, which involves retraining an LLM on your specific data. Fine-tuning is prohibitively expensive, time-consuming, and still results in a static model. RAG, on the other hand, allows you to continuously update your knowledge base without touching the underlying LLM, making it the most agile, cost-effective, and powerful strategy for enterprise LLM integration.
2. A Comprehensive Step-by-Step RAG App Development Blueprint
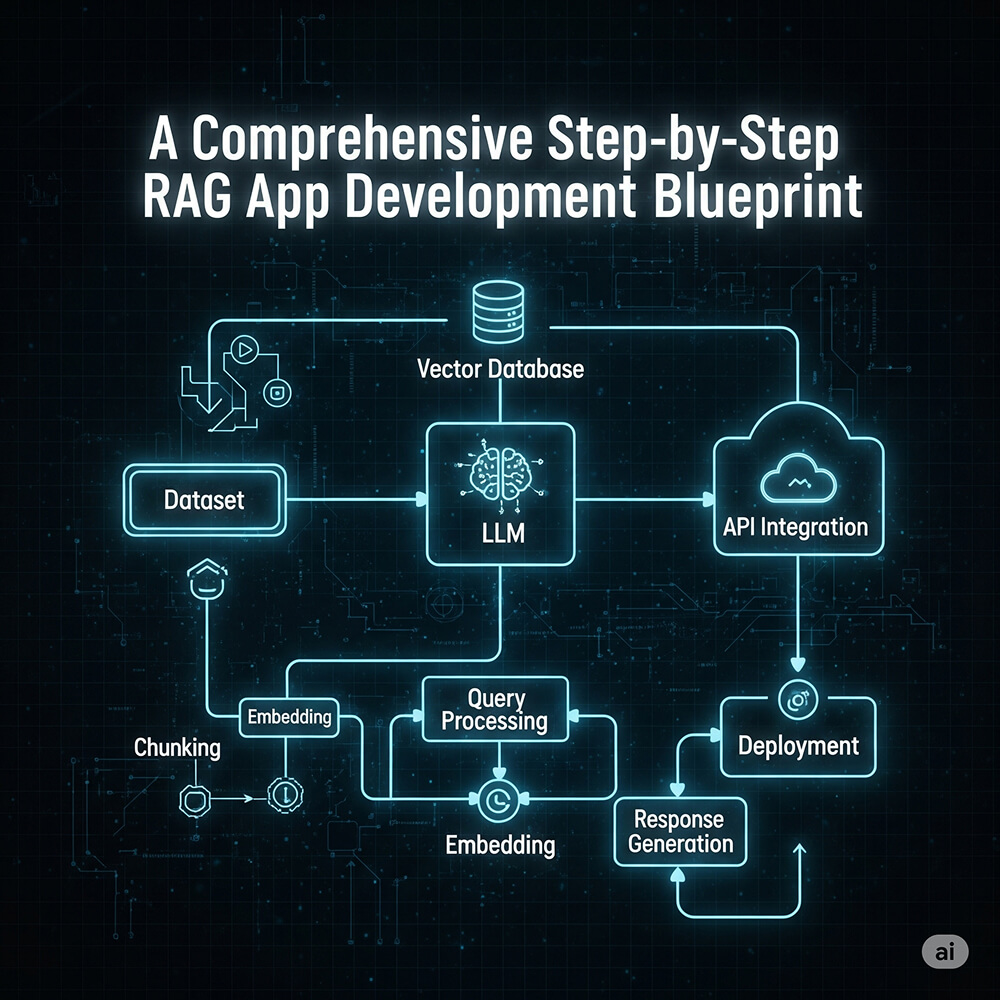
Building a RAG application is a multi-disciplinary effort that requires a clear, structured plan. Here is a detailed blueprint for a successful development process.
Phase 1: Strategic Planning and Data Foundation
The foundation of any successful RAG app is a well-defined strategy and a robust data pipeline. Don't rush into code without a clear understanding of your goals.
- Define a High-Impact Use Case: A common pitfall is trying to build a "do-it-all" AI. Instead, focus on a single, high-value problem. Is it automating a specific part of your customer support? Providing instant access to legal documents for a small team? A narrow, well-defined scope ensures a clear path to measurable ROI.
- Identify Your Data Sources: Map out all the data that will form your knowledge base. This can include unstructured data (PDFs, Word documents, emails, chat logs, meeting transcripts), structured data (databases, spreadsheets), and semi-structured data (JSON files, web pages).
- Data Preparation and Chunking Strategy: This is a crucial, often-underestimated step. Your raw data needs to be cleaned and pre-processed.
- Data Cleaning: Remove irrelevant data, correct formatting errors, and handle duplicates.
- Chunking: The way you split your documents into smaller chunks (the maximum amount of text you can pass to the LLM) directly impacts retrieval accuracy.
- Fixed-Size Chunking: Simple and fast, but can split sentences or paragraphs unnaturally.
- Recursive Chunking: A more sophisticated approach that tries to preserve semantic meaning by splitting documents based on a hierarchy of separators (e.g., paragraph, sentence, word).
- Context-Aware Chunking: Advanced techniques that use the content itself to determine chunk boundaries, such as splitting based on markdown headings or document structure.
Phase 2: The Modern RAG Tech Stack
Selecting the right tools is critical for building a scalable and maintainable RAG application.
The Large Language Model (LLM)
Proprietary Models
OpenAI's GPT-4o, Anthropic's Claude 3.5, and Google's Gemini 1.5 Pro are industry leaders, offering superior performance, larger context windows, and robust APIs. They are the best choice for a high-stakes, production-ready application.
Open-Source Models
Llama 3 and Mistral are excellent open-source alternatives. While they may require more in-house expertise to host and manage, they offer full control and can be more cost-effective for large-scale, self-hosted deployments.
The Embedding Model
This model translates text into vectors. The quality of your embeddings directly correlates with the accuracy of your retrieval. Leading options include OpenAI's text-embedding-3-large and cohere-embed-v3.0. For self-hosting, open-source models from the MTEB (Massive Text Embedding Benchmark) leaderboards are a strong choice.
The Vector Database
The backbone of your retrieval system.
Managed Services
Pinecone and Weaviate are fully managed, cloud-native solutions that handle the complexities of indexing, scaling, and searching for you. They are ideal for rapid development and enterprise-level production.
Self-Hosted Solutions
Milvus and ChromaDB are open-source, giving you full control and eliminating per-query costs, but they require significant DevOps and infrastructure management overhead.
Orchestration Frameworks
- LangChain: A highly versatile framework that provides pre-built “chains” and “agents” to connect various components of your RAG pipeline. Its modularity and large community make it the go-to for complex, multi-step workflows.
- LlamaIndex: Purpose-built for RAG, it excels at data ingestion, indexing, and structuring data to make it more usable for LLMs, with a focus on simplicity and ease of use.
Phase 3: Building the RAG Pipeline Architecture
The RAG architecture is a series of interconnected services.
Ingestion Pipeline
This is a batch or streaming process that ingests your raw data, performs the cleaning and chunking, generates embeddings, and indexes them in your vector database. This can be a simple script for a small-scale project or a robust, event-driven pipeline for an enterprise system.
Query Service
When a user query arrives, this service first sends it to the embedding model.
Retrieval Service
The resulting query vector is used to perform a similarity search in the vector database. It’s also crucial to implement a re-ranking step here. After retrieving the top 10 or 20 most similar chunks, a smaller, more powerful re-ranking model can re-order them to ensure the top 3 or 4 are truly the most relevant, improving final answer quality.
Generation Service
The re-ranked chunks are passed to your prompt template, which is then sent to the LLM to generate the final response.
3. Bringing Your RAG App to Life: The Mobile Application Experience

While the core of the RAG system is a powerful backend, its success hinges on a seamless user experience. The most direct and personal way to deliver this experience is through a mobile application. This is where mobile application development becomes a critical part of the overall strategy.
A business might partner with a specialized mobile application development company to build the front end that consumes the RAG API. The role of a mobile application developer in this context is to create a fluid, intuitive interface that connects to the intelligent backend you have built.
Platform Selection
You must decide whether to build for a single platform (e.g., Android app development using Kotlin or Java) or a cross-platform solution. For many companies, a cross-platform framework like Flutter is an ideal choice. It allows a single codebase to be used for both Android and iOS, significantly reducing development time and cost — a major concern when considering the total cost of a mobile phone application development project.
API Integration
The mobile application sends user queries to the RAG backend via a REST or GraphQL API. The app will need to handle network requests, display loading states, and present the final response in an easy-to-read format. This is where the true value of an integrated AI system is delivered directly into the user’s hand.
4. A Granular Cost Breakdown for RAG App Development
The cost of RAG apps is a major consideration for any business. It’s a dynamic sum of one-time and recurring costs.
Initial Development Costs (One-time)
These costs are tied to the human capital required to design, build, and deploy the MVP.
- Small-Scale MVP: A basic proof of concept with a single data source and a simple UI. Expect a small team (1 senior ML engineer, 1 backend developer) over a 2–3 month period, with costs ranging from $50,000 to $250,000. If you're building a simple front-end for your mobile application development, this cost will be on the higher end of that range.
- Enterprise-Grade Solution: A robust, production-ready system with integrations, advanced security, and a high-availability architecture. This requires a larger team (3–5 engineers, data scientists, a DevOps expert) over 6–12 months, with costs that can exceed $750,000.
Recurring Operational Costs (Ongoing)
These are the costs you'll incur after the app is live. For a high-volume application, these can quickly become the dominant expense.
- LLM API Fees: Often the largest variable cost. For example, a mid-tier model at $2.50 per million tokens and 500,000 queries per month (~2,000 tokens each) would cost around $2,500 monthly.
- Vector Database Fees: Based on data storage and query volume.
- Managed Services (e.g., Pinecone): $100–$1,500/month for mid-sized deployments.
- Self-Hosted Solutions: No per-query fees, but pay for cloud infrastructure (VMs, storage).
- Cloud Infrastructure: Hosting backend services (API gateway, etc.) can range from $500 to $10,000+ monthly.
Hidden Costs
- Data Maintenance: Labor for updating and cleaning the knowledge base.
- Monitoring & Logging: Tools for performance and usage monitoring.
- Security & Compliance: Ensuring data privacy (GDPR, HIPAA).
- Scalability: Infrastructure and GPU upgrades as user demand grows.
5. Quantifying the ROI of a RAG App: Real-World Case Studies

The true value of a RAG app lies in its ability to deliver measurable ROI by reducing costs and increasing efficiency.
Case Study 1: Customer Support Automation at a SaaS Company
Problem: The company was overwhelmed with repetitive support tickets for common issues, leading to high support costs and slow response times.
RAG Solution: A RAG-powered chatbot that accessed their entire support knowledge base. Built using Flutter for a unified mobile experience for customers and agents.
- Cost Reduction: Automated 70% of tier-1 support tickets, saving $150,000 annually.
- Efficiency Gains: Reduced customer wait times from 12 hours to instant, improving satisfaction scores by 15%.
Case Study 2: Legal Knowledge Management at a Law Firm
Problem: Junior lawyers spent hours searching legal precedents and contracts manually.
RAG Solution: A RAG app indexed and searched internal legal documents. A mobile app enabled natural-language querying.
- Productivity Improvement: Reduced legal research time by 60%, saving ~$200,000 per lawyer annually.
- Revenue Generation: Enabled faster turnaround and 10% new client growth.
6. The Future Trajectory of RAG and Its Business Imperative
The journey for RAG is just beginning. As the technology matures, we can expect several transformative advancements:
- Multi-Modal RAG: Future RAG systems will retrieve and augment data across text, images, video, and audio.
- Hybrid RAG Architectures: Combining RAG with fine-tuning, knowledge graphs, and autonomous agents for more robust intelligence.
In 2025, RAG is no longer experimental — it’s a proven, strategic tool for building trustworthy AI-powered apps. For CTOs and product managers, adopting RAG means unlocking efficiency, new revenue streams, and a strong competitive edge. The time to start your RAG journey is now.
